by Serena Raymond on Apr 27, 2020 12:00:00 AM
In 2018, DNSFilter acquired the company Webshrinker, a company that utilizes machine learning technology to provide website screenshot and domain intelligence API services. We wanted to highlight the journey of how Webshrinker began and how far the technology has come.
How Webshrinker got started
Adam Spotton, now Head of Data Science at DNSFilter, started Webshrinker in 2012 as a screenshot-as-a-service company. Initially, the product was created to fulfill a need for educational use. A provider of curated lists of educational websites needed to provide thumbnails of the website resources but there were thousands of websites to screenshot.
Rather than do work manually or use an incomplete solution (there was only one other screenshot-as-a-service at that time), Adam built Webshrinker to automatically take screenshots of sites that could then be embedded in the educational resource solution, reducing countless hours of manual work.
In 2015, Webshrinker grew as domain categorization was added and became the main driver of the product.
Using cloud computing and machine learning technology, Webshrinker classifies websites into sets of categories by scanning URLs. Users of Webshrinker are able to take the URL-to-category mapping (available to them as either an API or downloadable database) and use it within their software or services.
After a Kickstarter campaign in 2016, DNSFilter became a Webshrinker customer and began integrating Webshrinker’s domain categorization into the DNSFilter product.
Iterating on technology
Webshrinker has gone through many iterations but one of the main transformations has been the technology it uses to simulate a full browser session. Initially, it used Selenium. Then we moved onto a combination of PhantomJS and AWS Lambda. But this caused rendering issues that affected the screenshot API.
Now Webshrinker simulates an actual Chrome browser without using third-party libraries like Selenium.
This is one of the most important aspects of Webshrinker: its ability to imitate an actual person who starts a browser session. This is particularly important when it comes to threat detection.
When Webshrinker processes a page, it opens a browser simulation. If Webshrinker was not programmed to handle browser simulations in a way that mimicked human behavior and a human-initiated web visit, deceptive sites could actually deceive Webshrinker.
In addition to changes to the browser simulator over time, we also regularly pull lists of domains that have recently been flagged as malicious by the system so we can spot-check them for accuracy.
For instance, we might take 400 domains marked as phishing sites and run them through aggregate tools like VirusTotal. (VirusTotal is our standard benchmark because it is a collaboration of over 150 antivirus and domain scanning tools). This gives us an indication of how many false positives (non-malicious sites marked malicious) that Webshrinker is flagging.
This is an example of a VirusTotal spot check done on a Webshrinker-flagged malicious site:
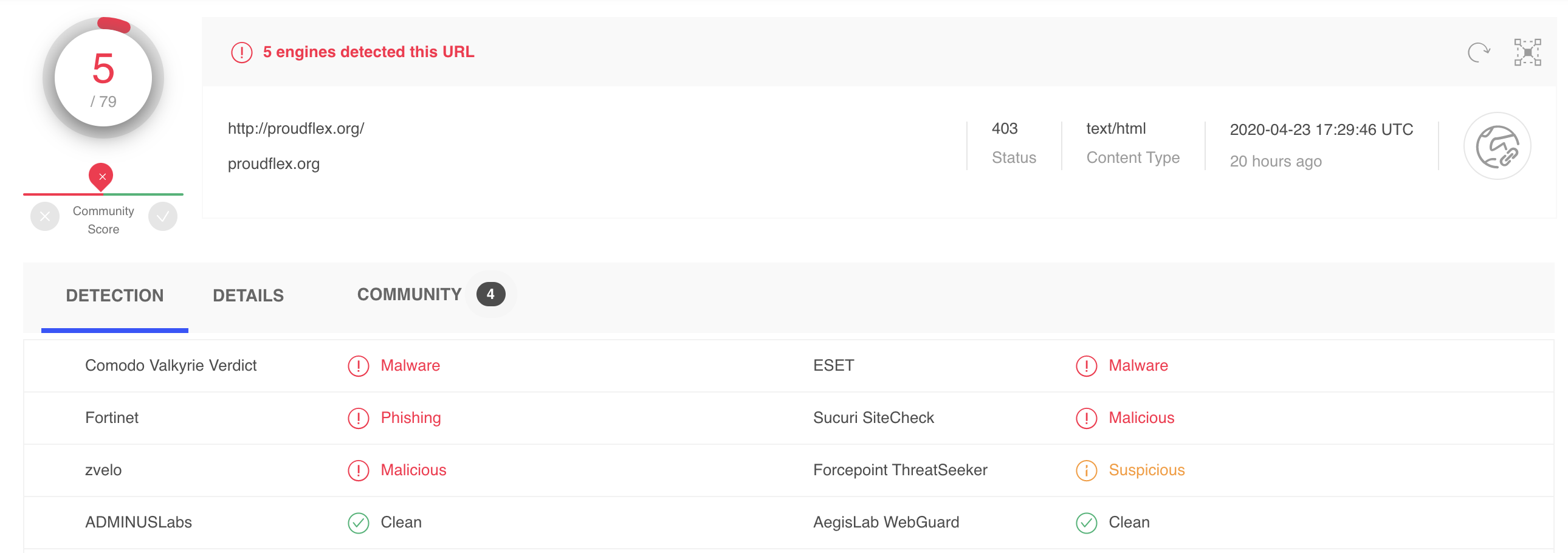
Doing these routine spot checks allows us to see where Webshrinker might be less accurate so we can continue to optimize the technology. As it stands right now, Webshrinker’s false positive rate is at roughly 4%.
Continued improvements
No software product is ever really finished, but especially not machine learning technology. We are actively working on making improvements to Webshrinker that will make it even more accurate. All of the spot checks implemented serve to make Webshrinker a stronger categorization tool.
We are also always optimizing the way that Webshrinker detects threats and feeding it sites to learn from. Doing this, we enable Webshrinker’s machine learning to better sort domains into malicious and non-malicious categories.
Planned improvements include creating additional, more granular categories. Eventually, image analysis will play a larger role in scanning the page during categorization to identify subcategories.
If you have a use for Webshrinker’s services, get in touch with us.
Part 2 to in this series shows how Webshrinker’s website categorization works.


