


Share this
by Serena Raymond on Apr 29, 2020 12:00:00 AM
This is part 2 in our mini-series all about our AI-driven domain categorization technology, Webshrinker. Read part 1 for more on how Webshrinker began and what the future has in-store. In this post, we go in-depth into how Webshrinker’s website categorization works.
How Webshrinker works
At a high level: Webshrinker will navigate to the requested domain or URL, fetch its content, and assign categories based on one of two taxonomies (native-Webshrinker categorization or IAB taxonomy) before going through threat detection. The end result is that the URL or domain can now be placed in a certain bucket depending on which taxonomy you’re using.
Additionally, a screenshot of what the destination looks like inside of a real browser (such as Chrome or Firefox) is also taken and made available through the Screenshot API service.
Domain ingestion
Webshrinker’s domain processing begins one of three ways:
- New domain ingestion—Webshrinker scans the web, crawling new domains and re-indexing previously categorized domains
- External feeds—external data sources that are given to Webshrinker to process
- Customer triggers—Webshrinker customers can initiate domain processing by requesting certain domains be categorized; on the DNSFilter side, if a DNSFilter customer visits a site that’s never been categorized, that domain will be sent to Webshrinker for real-time processing
Categorization
Once a domain has been ingested and passed the safety checks, it gets categorized. There are two options for categorization within Webshrinker.
The first taxonomy Webshrinker uses is its own native list of categories. These are the same categories that DNSFilter uses for content filtering. When you are using Webshrinker for the first time, this is the default taxonomy.

There are over 40 categories in total, making the list comprehensive but a little broader compared to other categorization taxonomies. This is ideal for DNSFilter, as we don’t want customers sifting through a list of hundreds of categories in order to determine which ones deserve to be blocked. Not only is this tedious work, but it can mean that things can get easily missed.
Webshrinker’s categorization is ideal for internet filtering and security applications, similar to how we’re using it in DNSFilter.
The second taxonomy that Webshrinker uses is from the IAB, which was referenced earlier. IAB stands for “Interactive Advertising Bureau.” They’ve created a standard list of categories and subcategories for advertising purposes.
As an example, if a marketer is putting together a campaign on Google Ads and only wants to show up on certain websites, Google uses the IAB classification to determine which category a specific domain belongs to. This means that if marketers are using Webshrinker to determine if sites are relevant for them to advertise on, the categorization that is given to them in Webshrinker is also used on advertising sites across the web.
Once Webshrinker is done categorizing a domain, that domain can then have multiple categories associated with it. A single site might only be placed in 1-2 categories within the native Webshrinker categorization or 1-2 categories using the IAB standards.
The IAB has nearly 400 categories to choose from.
As mentioned above, Webshrinker’s native categories are the default, but you can activate IAB categories instead if using Webshrinker for advertising purposes or if you need the extra granularity.
Threat detection
Webshrinker uses advanced Machine Learning algorithms to detect threats. And there are three major components of Webshrinker’s threat detection that make it incredibly good at detecting 0-day attacks.
Checking for threat markers
When evaluating domains, Webshrinker uses over 20 markers to determine if a site is deceptive or not. There is a certain threshold of markers, that if reached, will result in a domain being marked as deceptive.
This site was scanned by Webshrinker in April 2020. It hadn’t been picked up by any other third party feeds. Webshrinker was able to determine it was a phishing website based on the content of the site and structure of the page, despite on the surface it looking like a legitimate Chase banking login page:
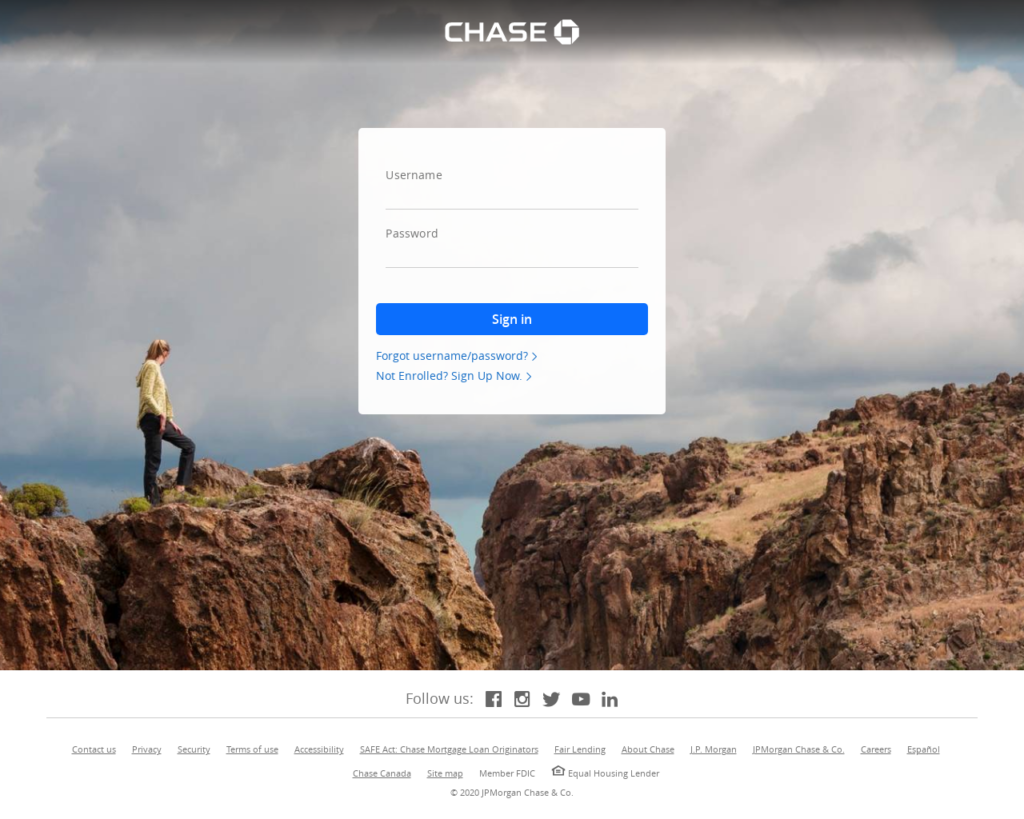
Browser simulation
We touched on this in our last post about Webshrinker’s machine learning technology, but we’ll go into it in more detail here.
When Webshrinker processes a page, it opens a browser simulation. If Webshrinker was not programmed to handle browser simulations in a way that mimicked human behavior and a human-initiated web visit, deceptive sites could actually deceive Webshrinker.
As an example, a phishing website might have something in place where it shows as a phishing website to humans but to bots that might be crawling sites, it shows as a non-deceptive site. Instead of a deceptive login page the bot might just see something benign, like a picture of a cat.
But because Webshrinker does not give any indication to the site it is visiting that it is not a human, it is able to process the actual phishing page.
While this is helpful in Webshrinker detecting phishing sites, it’s also important for categorization as a whole. After all, sites that might be categorized as gambling, pornography, or violent (to name a few), might also wish to disguise the nature of their site to avoid getting blocked by content filters such as DNSFilter. A gambling site might try to appear like a news site, so that they still show to an employee whose workplace blocks gambling sites during work hours.
Because Webshrinker is able to camouflage itself so well when processing domains, both its threat detection and domain categorization are more precise than other vendors.
Image analysis
Webshrinker is particularly good at detecting phishing sites, especially ones imitating banking sites. This is in part due to Webshrinker’s image analysis capabilities.
With every scan that Webshrinker does, there is a certain level of image analysis done.
As the content is evaluated, the system assigns certain score values to different aspects of it. If these score values are small then the system has enough confidence that the content is legitimate and not deceptive or phishing. If they are high, the system will flag the content as being deceptive.
If, however, the score values are in the middle and it’s not clear either way, a higher level of image analysis is performed. This extra step provides even more information to the categorizer to decide whether to classify something as deceptive or not.
Webshrinker is also able to match on-page logos to a logo database and spot fakes based on the logo itself and also where it is on the page. If you still have any burning questions on how Webshrinker works or how you might be able to get the most out of it for your unique use case, get in touch with us.
Share this
 Tycoon 2FA Infrastructure Expansion: A DNS Perspective, and Release of 65 Root Domain IOCs
Tycoon 2FA Infrastructure Expansion: A DNS Perspective, and Release of 65 Root Domain IOCs
Our analysis of Tycoon 2FA infrastructure has revealed significant operational changes, including the platform's coordinated expansion surge in Spanish (.es) domains starting April 7, 2025, and evidence suggesting highly targeted subdomain usage patterns. This blog shares our findings from analyzing 11,343 unique FQDNs (fully qualified domain names) and provides 65 root domain indicators of compromise (IOCs) to help network defenders implement mo...
 The Best Content Filter Software Checklist: A Buyer's Guide to DNS-Level Protection
The Best Content Filter Software Checklist: A Buyer's Guide to DNS-Level Protection
Staying Ahead with Smarter Web Filtering
Across every industry and network environment, content filtering isn’t just a matter of productivity, it’s a front line of defense. From malware and phishing to compliance risks and productivity drains, the threats are real, and the stakes are high.
") Smarter DNS Policies: What You Should Be Blocking (But Probably Aren’t)
Smarter DNS Policies: What You Should Be Blocking (But Probably Aren’t)
DNS filtering is a foundational layer of defense and helps to fortify the strongest security stacks. Most organizations use DNSFilter to block the obvious: malware, phishing, and adult content. That’s a great start, but many are missing out on the broader potential of DNS policies.