by Serena Raymond on Sep 13, 2023 10:09:00 AM
At DNSFilter, we’ve never had a global outage. You’ve probably heard us say that before. We repeat that because it’s something we’re proud of, and we’ve done a lot of work to ensure that our DNS network (our anycast network) has 100% uptime. What I want to address here is how we achieve that uptime.
We take pride in this because most other DNS filtering providers don’t go to the lengths that we do to ensure our network is both fast (we’re the fastest DNS resolver in the world and North America according to dnsperf.com) and redundant. We’ll explore here how and why our network was built to be resilient.
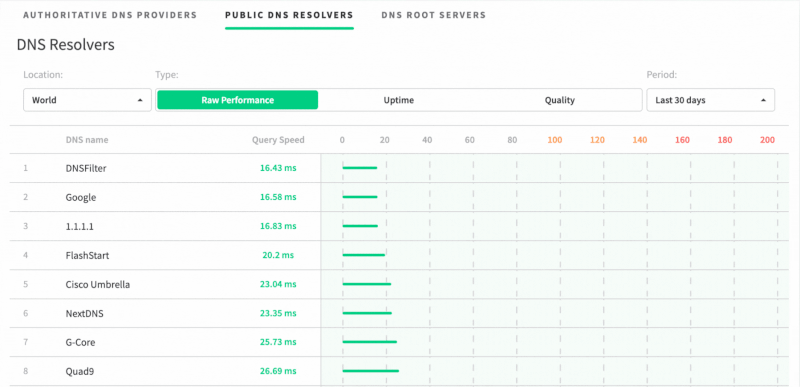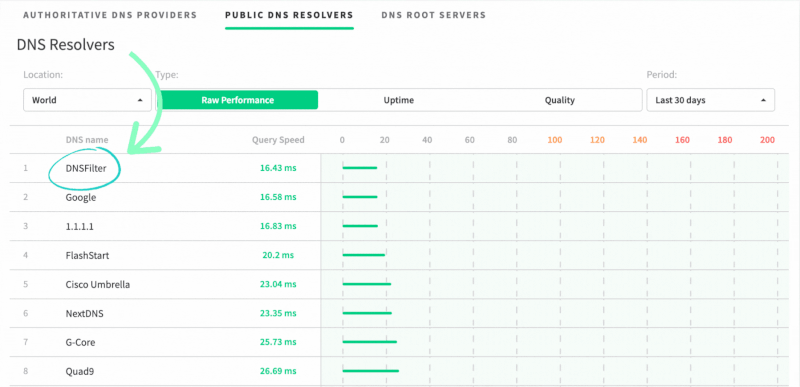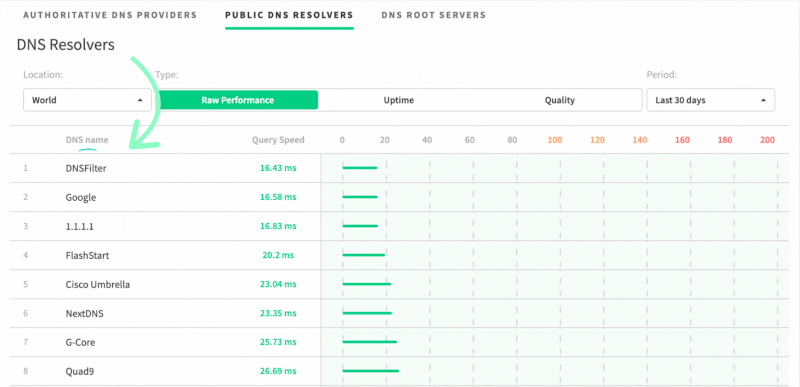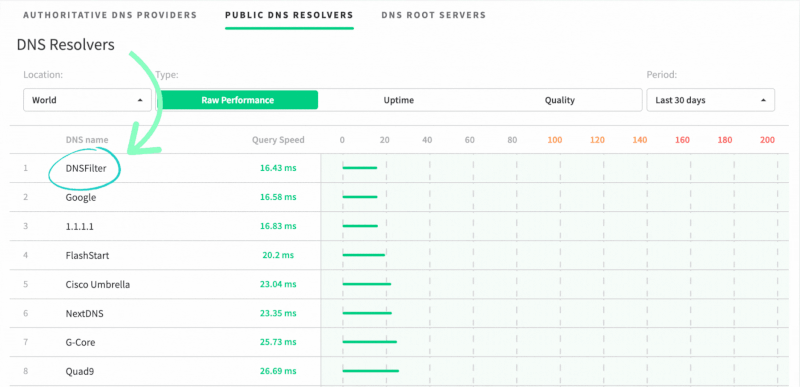
Our DNS network
Anycast is a way to route a network when there are multiple routing paths available. In our case, we have nearly 90 data centers globally in over 60 cities that someone’s DNS request might go through. We announce the same IPs from those data centers, from Singapore to New York City.
Our users point their DNS requests to the IP addresses we supply. Depending on which data center you’re closest to, your DNS requests will be sent to that data center. So if you’re in Germany, your requests might go through our Frankfurt location, while if you’re in the Pacific Northwest your requests will likely go through our Seattle location.
We’re able to do this through BGP (Border Gateway Protocol) and announcing our IP space from multiple locations; this is what enables anycast. We use a technology called ECS to pass along a portion of your source IP so that authoritative DNS servers and CDNs can determine your “true” location and point you to the best servers for them. Using that information, our servers send your DNS requests to the closest server based on your location. As an example, if you’re in Portland, using our Seattle anycast POP, but the website you’re using happens to have a Portland CDN location, ECS will enable that provider to send you to the Portland CDN location instead of the more-distant Seattle location. This results in a much faster experience for you as an end user.
This differs from the alternate method used in DNS resolution by other providers called unicast. In a unicast network, a single server is spun up in a single location. This means, whether you get online in Frankfurt or Seattle is irrelevant. No matter what, your DNS requests will travel to the same server. This is not an optimal method in DNS resolution as it creates more latency and higher end-user risk because if that single server goes down, everything goes down.
But, our service is actually comprised of two separate anycast networks (DNS1 and DNS2).
So if you’re in Germany, and you send a DNS request but DNS1 doesn’t answer, DNS2 will return your request instead with no impact on speed.
Further, the parts that make up DNS1 are not identical to the components that make up DNS2, even in the same city. For instance, we use Hurricane Electric for DNS1, but not for DNS2. That’s because if we only used Hurricane Electric and they had a global outage, so would we.
Our DNS1 and DNS2 networks are totally different. We use different hosting providers, data centers, and server architectures. This same strategy is actually used by the root DNS servers of the Internet. Setting up our network in this way benefits our customers by protecting them from issues that could be caused by our third party providers, such as:
- Hard drive failure
- Power loss
- Network connectivity
Further, if both Frankfurt servers were to go down, you wouldn’t be completely out of luck. The BGP routing in our anycast network would start sending your requests to the next nearest node, and we’d be working with our third party providers to get both Frankfurt nodes up and running.
Lessons learned in DNS networking
We never said we were perfect! While we’ve always run on an anycast network and had that vision from the start, we’ve run into many situations that have illuminated the need for changes within our process.
When we initially built our anycast network in 2015, we primarily had clients on the US east coast and Canada, but we needed to be ready to expand. So we built a DNS network where we could add new servers as our customer base grew, enabling us to reduce latency despite increasing the number of DNS requests we’d be resolving.
In 2017, we started using two global anycast networks: DNS1 and DNS2. We did this in collaboration with Packet and NetActuate, two flexible hosting providers that enabled us to use the same IPs across both platforms. This technology helped us create our fully redundant anycast network.
Another occasion where we learned from our mistakes occurred in 2019. We experienced an incident after updating a few anycast servers, but failing to create a flag that would stop BGP from announcing before those updates. Because of this, we caused errors to a small subset of customers. In total, this impacted less than 20% of our dns1 anycast network for 5 seconds and remains our largest outage to date. After this, we modified our testing environment and sent instructions to our clients who were immediately affected.
The redundancy we’ve built into our product, through our DNS1 and DNS2 anycast networks, is a major part of the foundation of DNSFilter. From the beginning we’ve strived to provide a product that will work for the end user, no matter what might be happening on the server-side behind the scenes.
Our customers shouldn’t have to worry about things like that! It should just work.


