by Jen Ayers on Oct 7, 2021 12:00:00 AM
The Facebook outage this Monday was the 5xx error heard all around the world. Facebook, Instagram, and WhatsApp went down but they took a lot of other services down with them.
And while DNS records were involved (and we originally thought this might have been the cause), DNS wasn’t to blame. While the issues manifested as DNS errors, the cause was something completely different: BGP.
Imagine a meteor landing in the ocean. The closest shore is hit with a tsunami. However, every connected body of water will still be impacted in some way—no matter how small.
This is what happened with Monday’s outage.
The Facebook outage: What happened?!
According to the statement released by Facebook, this is how the error occurred:
During one of these routine maintenance jobs, a command was issued with the intention to assess the availability of global backbone capacity, which unintentionally took down all the connections in our backbone network, effectively disconnecting Facebook data centers globally. Our systems are designed to audit commands like these to prevent mistakes like this, but a bug in that audit tool prevented it from properly stopping the command.
The command here was a change to Facebook’s BGP (more on that in a bit). Though the error had nothing to do with DNS from the onset, all of these domains became inaccessible and returned:
$ host facebook.com 1.1
Using domain server:
Name: 1.1
Address: 1.0.0.1#53
Aliases:
Host facebook.com not found: 2(SERVFAIL)
Because of how DNS works, we recognized early that if Facebook and associated apps are down, social sign on would be impacted. After all, logging into your Medium account through your Facebook account would require a DNS query to Facebook. If the Facebook domain is inaccessible, that query will fail.
At this point, we knew there were three domains down and countless other sites and applications impacted by the failure of social sign on. But what took other services down has to do with a mass of DNS requests essentially going nowhere (as there were no Facebook servers online to be reached) and timing out.
Andrey Meshkov of AdGuard described the issue they encountered in a series of tweets. DNS queries for AdGuard were unimpacted until Facebook made a change that caused queries to time out as opposed to just failing. That meant each query spent more time trying to resolve, all while going through DNS encryption which prolonged the time of the query. This caused an outage for them.
Other services experienced similar technical issues.
How was DNSFilter impacted?
In short, we weren’t.
Unlike AdGuard, we do negative caching, and our network is built to handle billions of queries in a day. When we looked at the data on October 4, we were the least-impacted DNS resolver to the best of our knowledge.
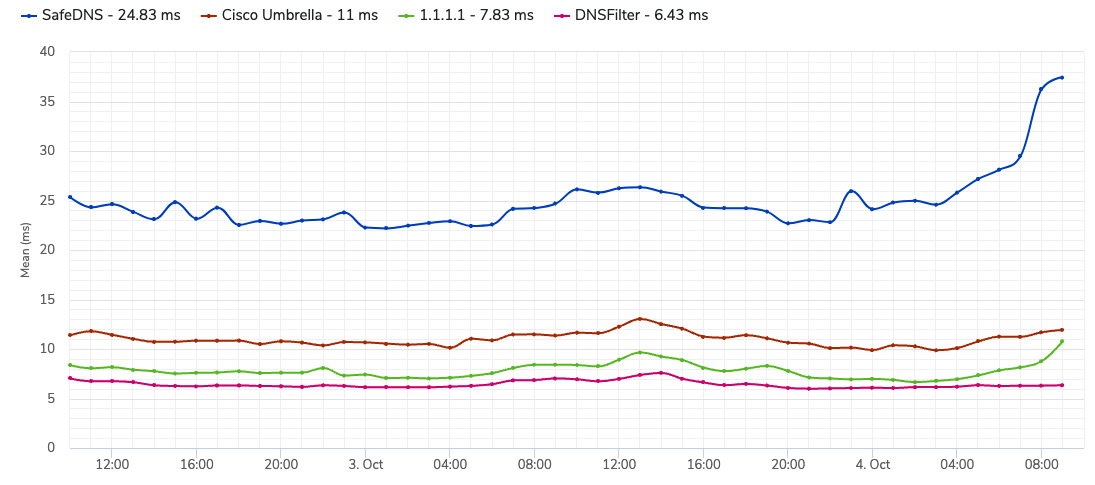
SafeDNS’ impacted service, in particular, seems to have led to an Azure outage—they likely had a very similar experience to AdGuard. ConnectWise was also affected, though the origin of their impact (outside of Facebook itself) is unclear.
On our network, we actually saw an increase in traffic to these sites as opposed to attempted access to these sites plummeting. This makes a lot of sense based on what AdGuard saw on their network, but it could also mean:
- The spike was human driven—the panic “refresh” clicking when something doesn't load. Or,
- The spike was system driven—where a system retries repeatedly because the 'ack' is not responsive.
The following images are a 7-day snapshot of our network, with the final day (and spike) being Monday, October 4, 2021:
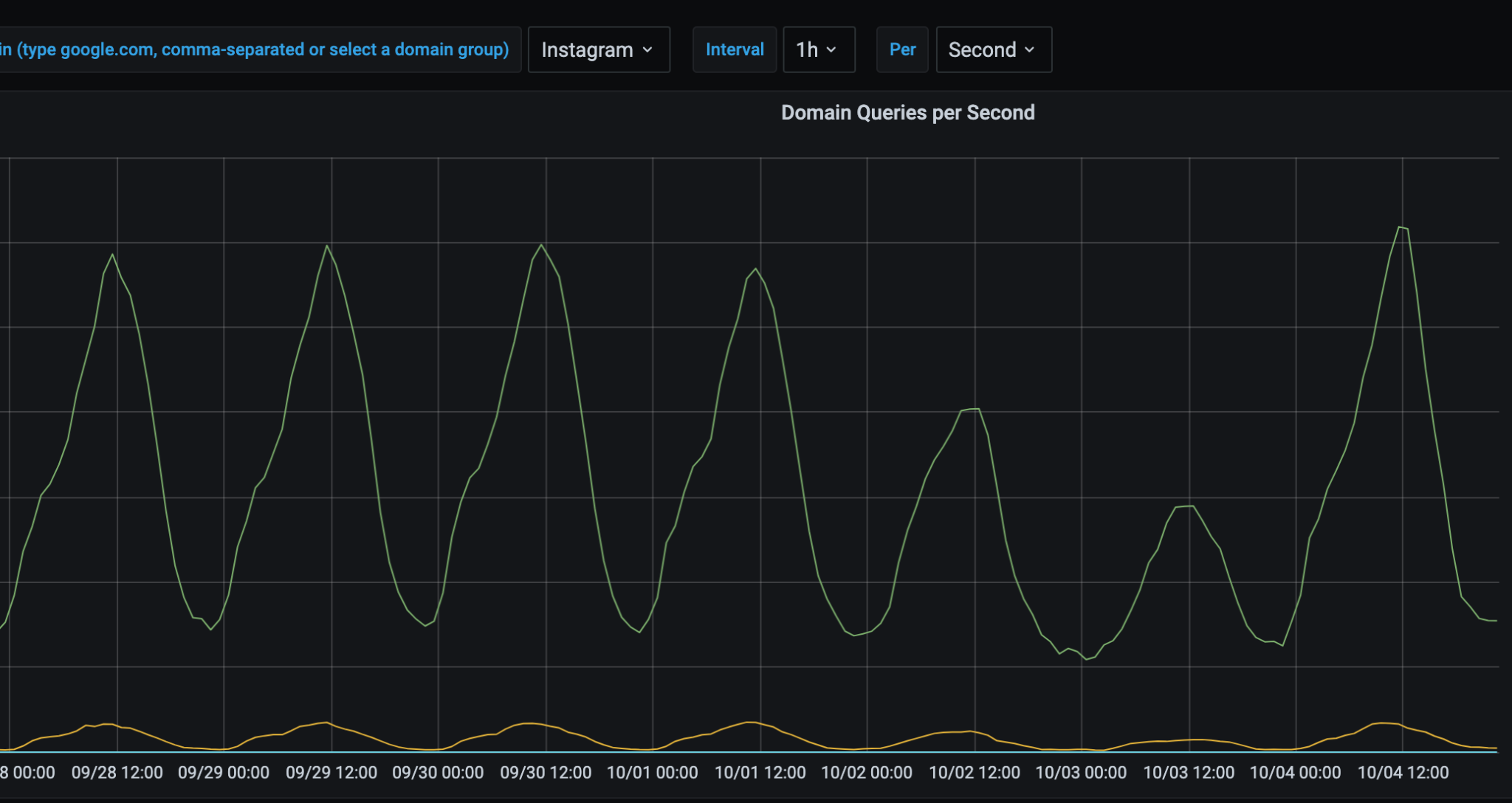
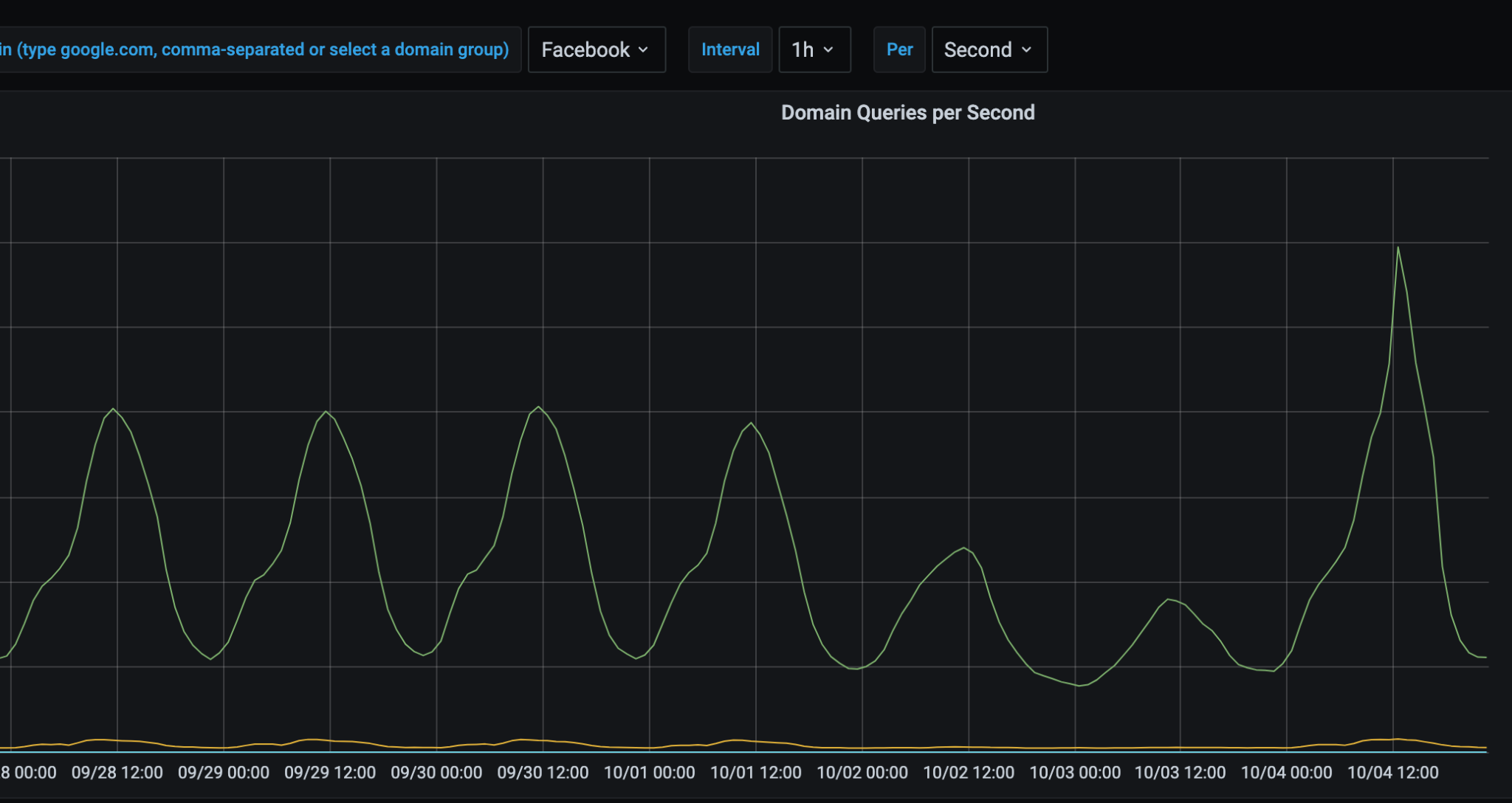
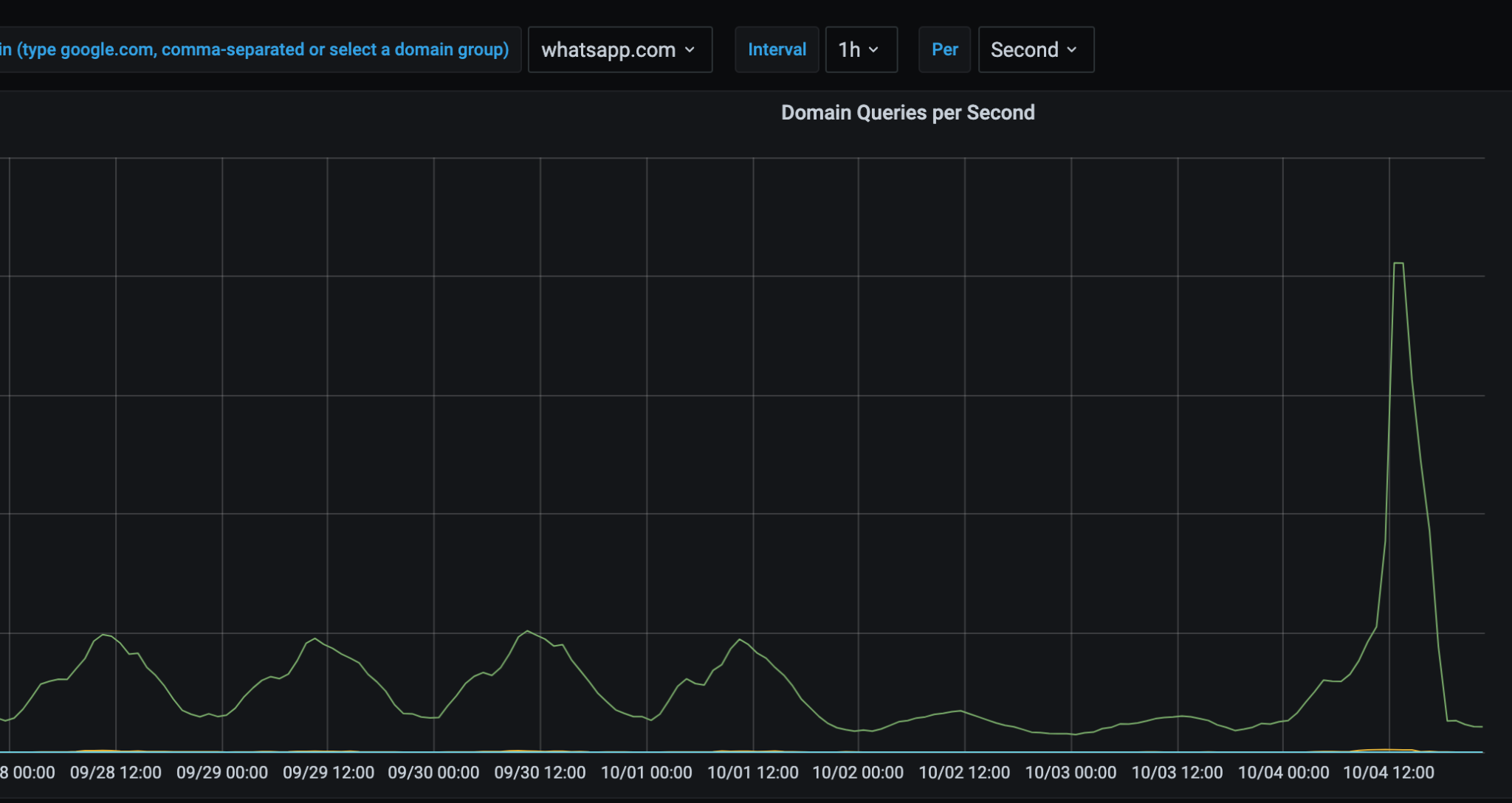
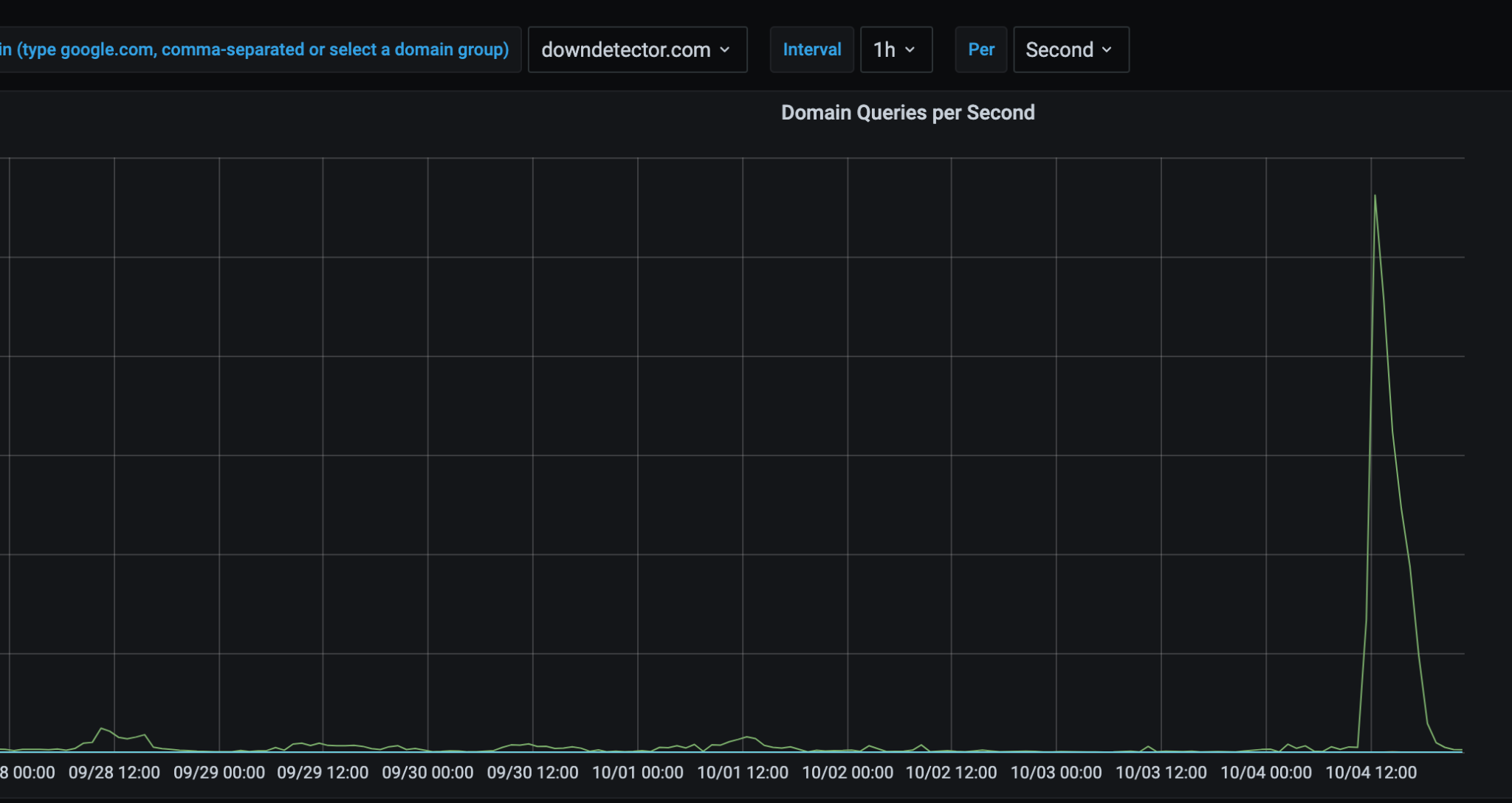
And likely unsurprising to probably no one, Down Detector saw a 5x increase in traffic that day:
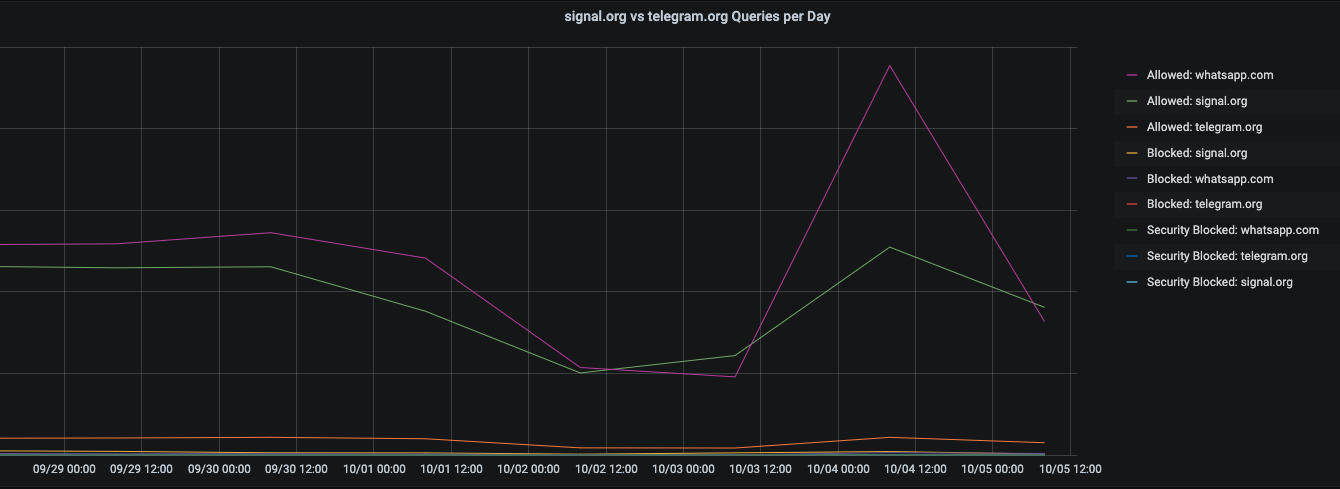
On LinkedIn, my friend and CEO of Ubiq Security, Wias Issa, posed the question: Did Signal or Telegram get an uptick in app downloads during the WhatsApp outage? We took a look at our network, and WhatsApp still held the top spot for queries that day, though Signal did seem to see some uplift from the outage. (Check out the presentation Wias and I did on double extortion ransomware for more great ruminations).
So...What’s BGP?
It stands for Border Gateway Protocol. The internet is built on BGP. We run BGP at DNSFilter. BGP routes packets from network to network and provides stability by accounting for failure. If something goes down, BGP can find a new path and reroute packet requests. It is a highly redundant, reliable system. However, making changes to the core of the system and taking it offline (like what Facebook did) can have far-reaching consequences.
No, it’s not always going to be BGP. But at least this time, it wasn’t DNS.


