by Henri Laakso on Jun 10, 2022 12:00:00 AM
Like most cybersecurity providers, DNSFilter supplements its in-house data with third-party threat intelligence. This comes from a collection of more than 60 different paid and open sources, amounting to millions of reports on domains.
It is important for us, like any organization, to regularly analyze our portfolio of threat intelligence. This article covers a range of techniques to gain insight into our collection of third-party threat intelligence.
Comparing threat feeds by size
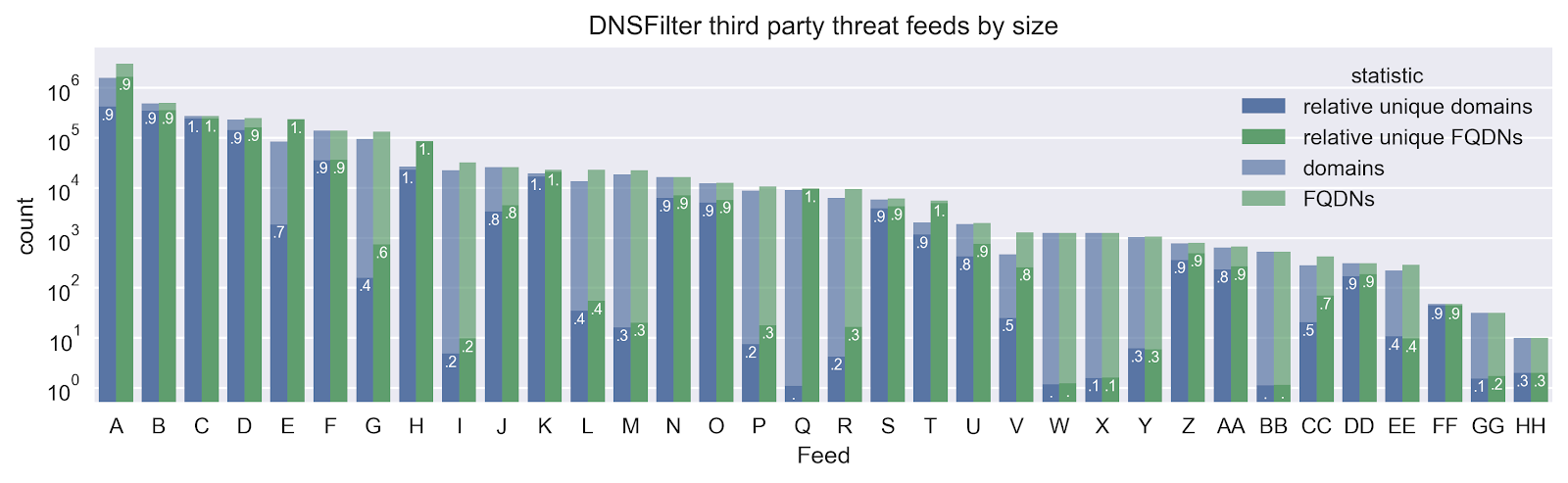
The DNSFilter collection of third-party threat intelligence covers a large span of feeds, by size, as seen in Fig. 1 (below). This is to be expected as feeds are generated via different techniques, cover different threat types, and have different levels of focus.
How does DNSFilter compare domains?
When comparing domain name threat data, it is important to choose which label-level this is done at.
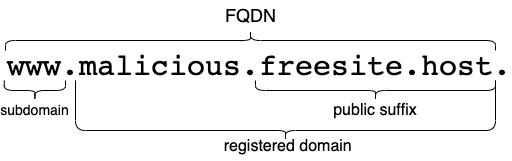
For this reason, for the rest of the article 'domain' is used to refer to the domain name down to the highest blockable label. Otherwise FQDN is used.
In this context, it can also be of interest to look at the amount of reported domains and FQDNs which are unique to each feed. Let’s use Feed Q as an example. Almost all the FQDNs in Feed Q are unique but the domains are mostly overlapping with other feeds. It could be further analyzed if this feed is bringing value and if these subdomains are blockable at a higher level.
How fresh is your threat intelligence?
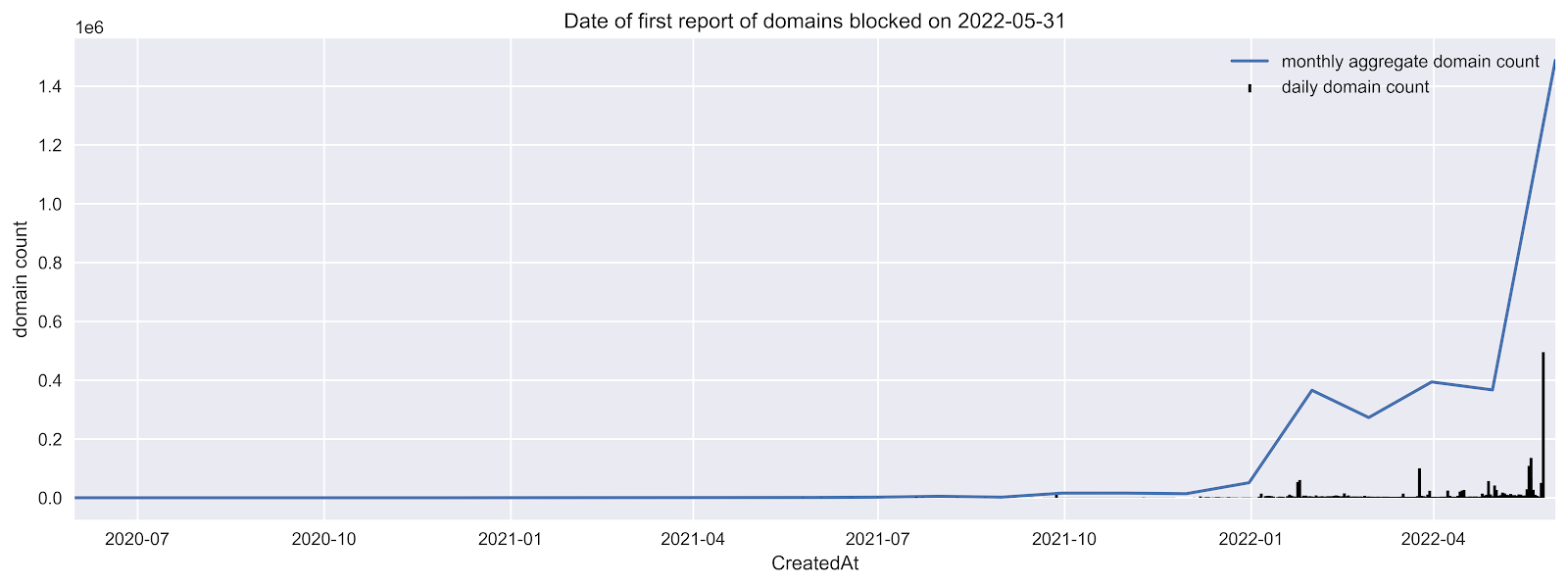
It is important to keep fresh intelligence, as stale data can be irrelevant or, worse, inaccurate. Many threat intelligence sources do not age out their data so this is left to the customer. As time goes by, the chances of a false positive increase.
From Figure 2, it is clear that the vast majority of DNSFilter's third-party threat data is fresh. The vast majority of domains were added in the last few months, with a small number of domains older than a few months. Spikes on specific days can correspond to new feeds, which are continually added by our team.
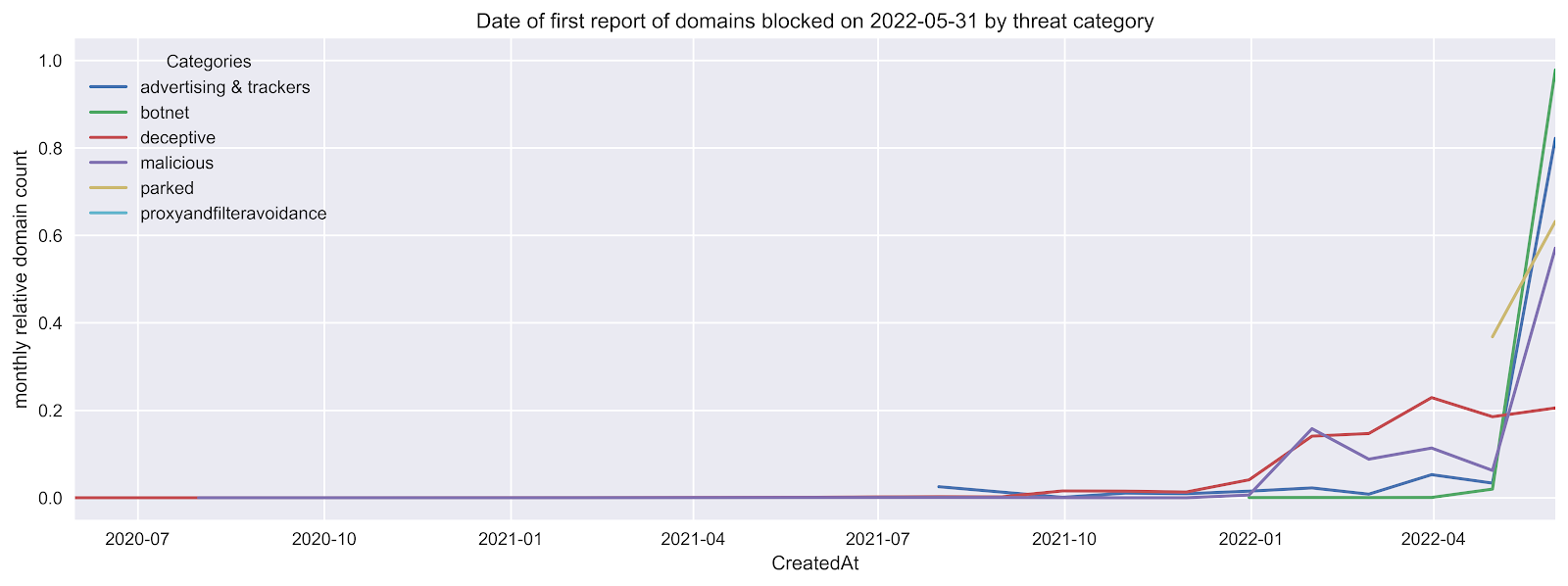
We can break this down by threat category. As expected malware and botnet C2 domains are transient and age out quickly. Deceptive domains, which include phishing and scam domains, age out over a period of several months as campaigns are rolled out.
Do your threat feeds overlap?
A closer look at how feeds overlap shows a very sparse set of data, with a few exceptions. Figure 4 shows very little consistent overlap between feeds. Even for the largest feed, Feed A, the majority of the overlaps are below 20% of the smaller feed.
In some very specific cases, such as Feed W & Feed X, the overlap is significant. This is understandable, as they aim to cover the same specific threat actors. This and other significant overlaps could also represent data sharing agreements.
The figure shows the reasoning for using a multitude of feeds—the threat intelligence space is very sparse. This result is consistent with many other similar studies, which indicate that a single source of ground truth does not exist.

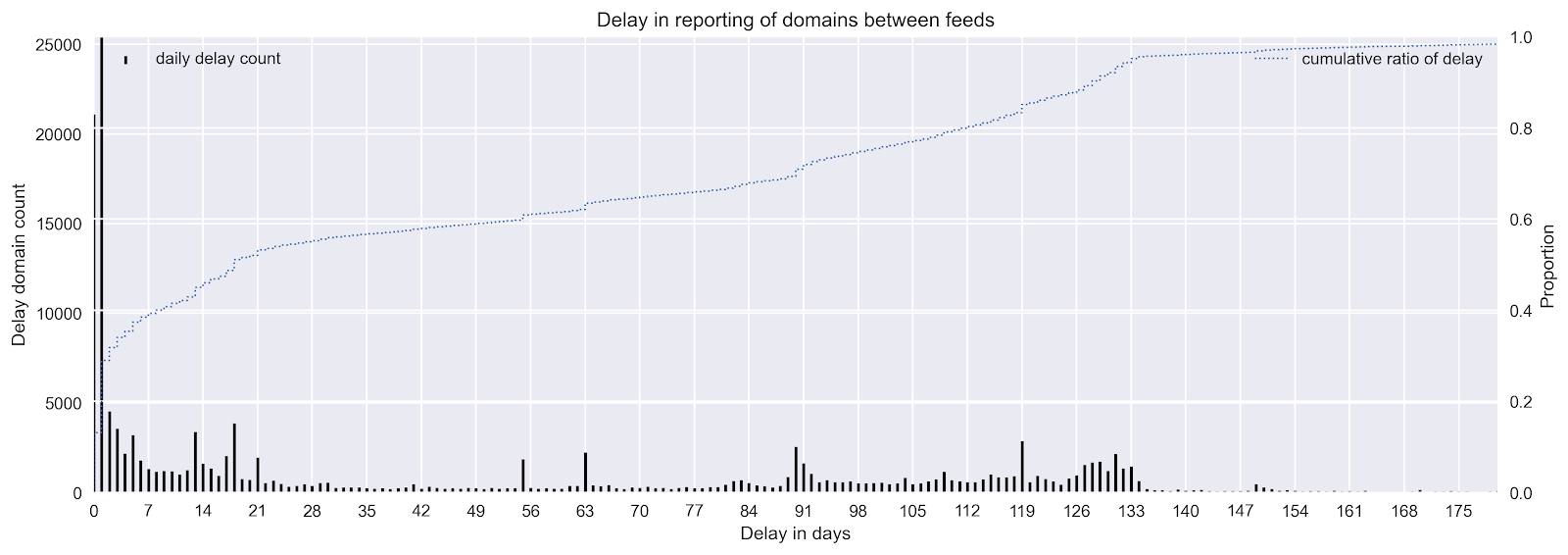
Delays in reporting between feeds
A static overlap analysis does not tell the whole truth, as it does not take timing into account. As timeliness is an important factor in actionable intelligence, this should be measured.
Figure 5 shows that most overlaps between feeds occur within zero or one days of the initial report. Roughly 50% of overlapping reports occur in the first three weeks. For cases longer than this, it is likely domains become non-malicious and then are caught again later. Large spikes in some cases indicate specific data sharing agreements between feed providers.
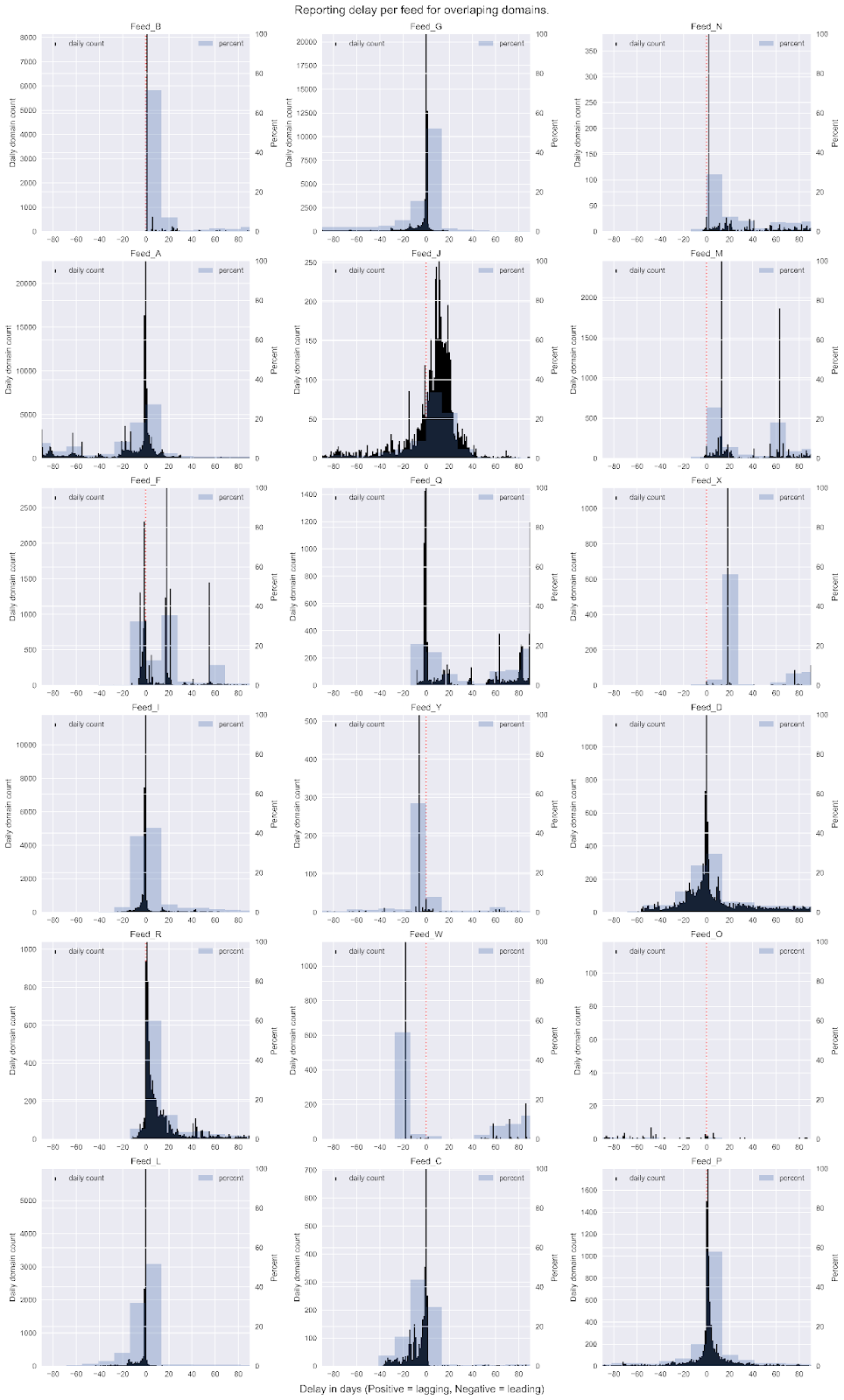
We can further break this down by individual feeds to see which ones are lagging (positive delay) and which leading (negative delay). This is shown for larger feeds in Figure 6.
The transfer of data between feeds W and X can be observed here again, occurring with a roughly 20 day delay in most cases.
The largest feed, Feed A can be seen leading in most overlap cases, showing the value of the feed.
Other feeds like feed J, have no clear relationship with other individual feeds, and the delay pattern resembles a poisson distribution, generally a result of a random process, although with a small skew.
Utilizing automated analysis techniques
This article shows a small number of analysis techniques that can be applied to a collection of threat data. As automation is increasingly used to generate threat data, it must also be used to evaluate it.
These analyses can reveal blindspots, redundancy, and value-for-money opportunities, and even technical issues. This helps make our selection of threat feed data as beneficial to our customers as possible by:
- Increasing our coverage of the totality of active cyber threats
- Reducing redundancy among feeds
- Ensuring threat data is timely
- Ensuring cost effectiveness of the threat feeds we purchase
Of course human analysis can never be replaced particularly when searching for ground truth, but these techniques can reveal where to start looking.


